No Compiler
On LLVM, using C libraries from Lua, and writing software without a compiler
I’ve been working on a programming language. I make video games, and the languages that exist for this all have drawbacks that get in my way when I’m making stuff, so I decided to make a new one. I made an interpreter, and it works, which is pretty awesome! But it’s too slow. For what I want to be doing, I decided, rather than an interpreter I ought to be writing a compiler. Once I realized this my project stalled out, because I just really did not want to write a compiler. It’s a lot of work, and a lot of things I’ve never done before, and I wasn’t really sure where to start, and I just really really hate writing parsers.
Then last week I got this weird idea.
If you look in a book about compilers, you’re inevitably going to see a diagram like this:
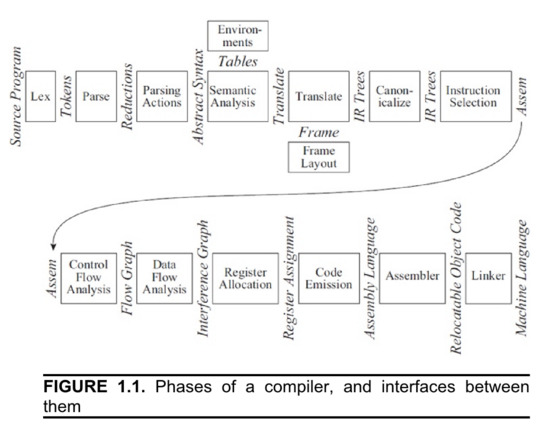
This diagram is from "Modern Compiler Implementation in Java", the book they gave me in college, and it shows all the steps a compiler takes in turning source code into an executable program. This diagram is also out of date. The modern diagram looks like this:
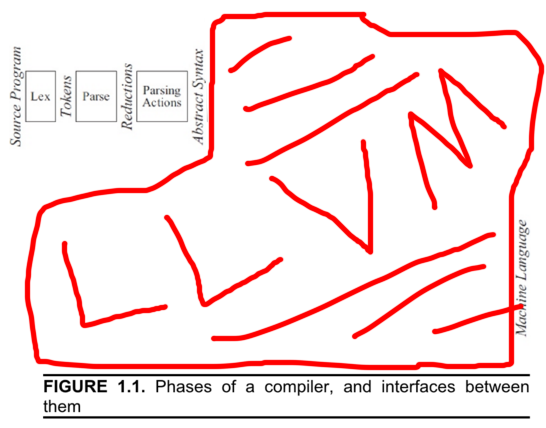
LLVM is a compiler "backend"— these terms are fuzzy, but people like taking that first diagram and dividing it in half between the "frontend", which in this diagram is the first three boxes, and the "backend", which is the rest. LLVM is the backend for Clang, but LLVM predates Clang and can be used as a stand-alone library. This has lead to a sort of renaissance in homegrown programming languages since now you don’t need to write your own compiler, you can just write a frontend and plug it into LLVM.
And increasingly, this is what everyone does. You could write your own backend, but LLVM is a good backend, and it has about a zillion targets, and it has the combined engineering efforts of Apple and Google (and, now, Microsoft) improving it, and in practice you’re not going to write a better one. You might be able to write a backend which is in some way more apt for your particular use case, but you’re not going to write a better general one. And actually we’re now entering a world where at minimum supporting LLVM as a backend option is mandatory. Apple is aggressively moving to a model where you are no longer allowed to write your own compiler, and for certain platforms (the "Watch", and for a while they were trying to force this for the "TV" as well) you can’t actually create software, you just create bitcode (a binary representation of that "abstract syntax tree" from the diagram) and Apple compiles it for you with their copy of the LLVM backend. Which is sort of horrifying, and yet another example of how Apple’s burgeoning monopoly power f— um, anyway.
Where I’m going with this:
Many years ago, I used to write a lot of audio software. I was making music, and I’d make little programs to make music with— tiny instruments and such. My big dream for a long time was to eventually write a sequencer. I’d play my little homemade software instruments, and I’d play normal physical instruments, but then if I wanted to fit them together into a song I’d have to use sequencer software someone else wrote. This meant I never really had as much control over how things were timed or mixed together as I wanted, so I wanted to write my own sequencer. But that turned out to be hard. There was a lot of UX to design and a lot of lines of GUI to write. All my attempts failed. Eventually what I started doing instead was writing little single-song sequencer programs with no GUI. I’d write a tiny C program for each song, and each program would load the recorded tracks and samples from wav files in its directory, mix them together exactly however I’d described in the C code that it should, and spit out a wav file at the end. This worked really well! The songs sounded good and it was fun as heck. And because I was doing the mixing "by hand" instead of trying to express what I wanted to the intermediary of a sequencing program, I could direct my code on a whim to do complex things that would have been ridiculously difficult to represent in a GUI, things "wait until track 3 goes over this amplitude twice and then immediately cut in track 4".
Now, with Emily (my programming language project), I feel like I have a similar problem. I have things I want my games to do but which I have difficulty expressing elegantly to the tools I have. So I want to make a new tool— but this ultimately means I’m going to design a language that I can express complex ideas to, and then write a compiler that turns that language into LLVM ASTs, and then only after I’ve done all that do I get to start actually expressing my ideas to the language I designed. But I’m stuck on the difficulty of those first two steps— finding a good fixed medium through which to convey my thoughts to my compiler frontend, and then getting the frontend to translate that into LLVM. The "UX" part.
So here’s my weird idea: What if I just did what I did back when I was making music, and cut Emily and her compiler out of the loop completely, and wrote the LLVM ASTs myself? I could easily imagine writing a program that calls the LLVM AST construction functions until it’s described a program, and then directs LLVM to emit an exe. I would basically be writing software with no compiler. Or, maybe a different way of looking at it, is I’d be writing a lot of very small compilers, with no programming language, where each compiler emits only a single fixed program. Suddenly the diagram would look like this:

This sounds like a terrible idea. It also sounds hilarious. I’m gonna try it.
LLVM-C
In CS, we sometimes talk about "metaprogramming". This is a loose phrase for the idea that a language has exposed facilities for you to write code that will write other code for you. Sometimes this works pretty literally— if you look at C defines, or C++ templates, or LISP macros, what you’ve sort of got is a second programming language, semi-awkwardly embedded halfway into the first one, which generates code in the first language before the compiler/interpreter tries to run it. When I write my little not-compilers, I’ll be doing something like this; the language I write my not-compilers in will be my metalanguage, and the language itself will just not exist (or maybe, technically, be LLVM IR). The underlying language will be way too simplistic for writing anything meaningful at all in it to be convenient, so whichever metalanguage I pick had better be expressive enough to let me build within it all the abstractions I’d normally expect when writing software.
I picked Lua. Lua is my favoritestest programming language in the whole world, and nothing I’ve ever used beats it for flexibility. I don’t really use it anymore, because I kept running into practical problems when actually running my Lua programs (FFI/library support isn’t as convenient as it should be, GC is mandatory, it works badly with threading). But none of that is a problem here, because I won’t actually be running any Lua— Lua will only be a kind of build script.
One of the nice things about using Lua is LuaJIT, which is an interpreter implementation with a fairly unique FFI (i.e., its way of talking to software written in C). Usually talking to C libraries from a higher-level language like Lua is a pain where you use wrapper scripts, which generate copies of every single C function you want to call. These "wrapper functions" laboriously convert from however your language thinks about data and functions to the way that C does and, back. This is awkward, and bug-prone, and occasionally you’ll hit a point where C is using data in some way your language doesn’t even know how to describe and just get completely stuck. LuaJIT on the other hand does this completely different and sort of wild thing where it directly parses C header files at runtime, and then it just knows how to pack memory in such a way as to replicate C structs and calling conventions. This makes LuaJIT good for writing a script that mostly calls functions from a C library; LuaJIT can create C data items in memory and call C functions with them the same way a C compiler can, so using the LLVM libraries should be as easy as it would be in C.
There’s still a bit of a problem, which is that the LLVM libraries aren’t actually written in C. They’re written in C++. This is bad. C++ is basically total poison for language compatibility. C++ does not have what’s called an "ABI", which means there’s no standard for how functions call each other when you’re using libraries. Each compiler just kinda comes up with its own thing. This means not only is it impossible for languages that aren’t C++ to call C++ code, it’s not even possible for C++. Two C++ libraries using the same compiler can talk to each other, but if the person who wrote a library you want to use was using a different compiler than you (which on Windows, will happen frequently) there is nothing you can do.
Now, it does turn out— in part because they realized this was a problem— that the LLVM people also distribute a library named LLVM-C, which is a set of C wrappers to the underlying C++ API. Yay! Unfortunately, it’s sort of only half-supported. The LLVM-C documentation describes itself as "This module exposes parts of the LLVM library as a C API"— "parts of"? What the IRC channel explained to me is that LLVM-C is whatever parts of LLVM that somebody realized they needed and added to LLVM-C to scratch that momentary itch, piecemeal, at random times over the last thirteen years. Parts are missing, and the parts that are missing are totally random. Apparently there are still major projects using the LLVM-C interface, so this is not a reason to give up or anything, but this is still going to be a concern to be aware of moving forward. (Interestingly, the Rust people implemented their own equivalent of LLVM-C because they found LLVM-C wasn’t comprehensive enough— but, the Rust project LLVM C bindings are also a random set of whichever parts of LLVM the Rust people needed, it’s just a different subset from LLVM-C, so this does not help us here.)
Anyway, LLVM-C it is. I install version 3.9 (the latest) and download a copy of llvm-c-kaleidoscope— a C port of the program from the LLVM tutorial. I never do get llvm-c-kaleidoscope to compile, but that’s okay, it’s just for reference.
I’m now ready to start writing some Lua! I set up a little project:
config.lua generate.lua lib-ffi/ import.lua llvm/ 3_9/ (LLVM headers in here) lib-lua/ import.lua pl/ (Penlight in here)
Unfortunately, Lua doesn’t have a very good story for libraries. Unlike languages like Python that are expected to have a runtime with various niceties already installed on the computer, Lua was designed to be embedded into larger programs (for example, games). The assumption was whoever was doing the embedding would set up whatever libraries are needed. So if you’re running a Lua script standalone (like I’m doing here), you kind of need to set up a little environment around it with the basics. Here "the basics" are provided by Penlight, a third party "standard library" for Lua which includes a lot of basic stuff, like classes (yes, in Lua object oriented programming is something you get from a library— like I said, it’s flexible). Even just getting Penlight into the program is a little awkward; lib-lua/import.lua contains:
-- Lets internal references in Penlight work package.path = package.path .. ";./lib-lua/?.lua" class = require("pl/class") pretty = require("pl/pretty")
Yech.
Of more interest is the lib-ffi directory. This, too, is a little awkward. Like I said, LuaJIT consumes C header files, but it doesn’t do it the way a compiler does– there’s no include path, or anything. Instead you call a function named ffi.cdef with the header file contents passed in as a string. Except you can’t just put those contents in verbatim– LuaJIT doesn’t understand C preprocessor directives, so you have to strip those out first. Like I said, this is part of why I stopped using Lua– every time you bring in a new library there’s this labor-intensive process of massaging it so Lua can talk to it. In this case it doesn’t seem so bad though, because I only have to do it once, for the LLVM library (and maybe Clanglib at some point). Any libraries I use beyond that are going to be talking to my generated executable, not my Lua script.
I figure out which headers I’m going to need, and fill out lib-ffi/import.lua with:
ffi = require( "ffi" ) -- Libraries local libExt = ({ OSX = "dylib", Windows = "dll", Linux = "so", BSD = "so", POSIX = "so", Other = "so" })[ffi.os] local function libPath(name) return config.llvmLibPath .. "/" .. name .. "." .. libExt end LLVM = ffi.load( libPath("libLLVM") ) -- Headers local llvmDir = "lib-ffi/llvm/" .. config.llvmVersion .. "/" require(llvmDir .. "Types") require(llvmDir .. "Target") -- Requires Types require(llvmDir .. "TargetMachine") -- Requires Types, Target require(llvmDir .. "ExecutionEngine") -- Requires Types, Target, TargetMachine require(llvmDir .. "ErrorHandling") require(llvmDir .. "Core") -- Requires ErrorHandling, Types require(llvmDir .. "Transforms/Scalar") -- Requires Types
There are a couple of things going on here.
When you compile a C program, there’s a compile phase (which if you’re using a library, is when you interpret its headers) and a link phase (which if you’re using a library, is when you link the library binary in). LuaJIT does all of this at runtime, but it still needs the headers and the libraries. You feed it the headers as strings so it knows what memory layout to use, and then you give it the direct path of the library to dynamically load. It’s all manual and there’s nothing intelligent like a linker in play, so I have to do the legwork of figuring out things like what the file extension for a dynamic library is on the current operating system. There’s also absolutely no way for me to figure out where the LLVM libraries are installed, so I expect whoever runs this script to provide that path before running, in the config.lua file.
Then we get to the headers. I choose to version these, and make the user say which version they want in config.lua.
My goal is to create LLVM "abstract syntax trees". LLVM, as I understand it, has three ways to specify an AST: As LLVM IR, which is a textual representation of ASTs which changes with every version of LLVM; as bitcode, which is a binary representation which is standardized and compatible between LLVM versions; or by calling the functions in the LLVM or LLVM-C API. My understanding is that the LLVM-C API is stable— if you write a program targeting LLVM 3.6, you should be able to recompile with LLVM 3.9 and it should work. (If this is not true, please, somebody warn me now.) However, just because the 3.6 and 3.9 APIs are source compatible does not mean you can use the 3.9 headers with the 3.6 libraries. And I’m going to do something weird— I’m going to embed the 3.9 headers directly into my source repository, because I have to, because I’m loading my hand-massaged versions of the headers rather than the ones on disk.
Right now everything I’m doing is just a weird experiment— I’m not designing any of this to be convenient for other people to use. However, it seems like it would be pretty bad if I designed this in a way it literally only works on this one computer, with this one version of LLVM. Weird experiment or no I need to leave the door open for another human to run this, especially since anything that will trip up another human will also trip up my own future self. I open that door by leaving space for multiple versions of the "massaged" LLVM headers to be checked into this repository: I check in the 3.9-compatible headers I’ve got (in a folder awkwardly named 3_9, since the Lua loader can’t handle directory names containing periods), and expect that people using a different version of LLVM in future can at least do the conversion process on their own headers and check that in alongside 3_9.
With that established, I copy all the 3.9 LLVM-C headers into my 3_9 folder and check them in unchanged— I won’t be using them, but I want them around for future reference— and select the handful I need, the handful from import.lua, to convert to Lua. This process is mostly simple; I rename to .lua, delete the #if guards and #includes from the top and bottom, and stick ffi.cdef[[ at the top and ]] at the end. (The square brackets create a multi-line string.) Easy! Except:
- Since I removed the
#includes, I don’t get dependency management done for me. This means I have to work out the dependency tree by hand and make sure I include everything in the right order (hence the weird comments inimport.lua). Core.hcontains some trickery with#define— some C metaprogramming. I have to run the C preprocessor manually on this file (making sure to do so after I remove the#includes at the top, because otherwise I’d get the entirety of stdlib pulled in to the file).-
Target.his even worse— it contains this strange repeated preprocessor construction:/* Declare all of the target-initialization functions that are available. */ #define LLVM_TARGET(TargetName) \ void LLVMInitialize##TargetName##TargetInfo(void); #include "llvm/Config/Targets.def" #undef LLVM_TARGET /* Explicit undef to make SWIG happier */What is this? Well, apparently, when the LLVM libraries were installed on my computer, the install built these
.deffiles containing per-system configuration information. If you look inTargets.defin the main LLVM headers, you find it’s full of lines likeLLVM_TARGET(AArch64) LLVM_TARGET(AMDGPU) LLVM_TARGET(ARM) ...This is a problem. The reason I believe I can move my "massaged" 3.9 headers to another computer and have the code still work with the local dynamic libraries is I assume things like structure layouts don’t vary between any two compiled copies of a single version of LLVM. But, the .defs contents will vary from computer to computer! The only possible solution here is to leave the metaprogramming macro garbage in
Target.lua, and instruct anyone who tries to compile this code to run the preprocessor themselves (thus getting the.defcontents from their own computer). The project now has a README instructing users to run this monstrosity before running the not-compiler:gcc -I/opt/local/libexec/llvm-3.9/include -E -P -C -xc-header ./lib-ffi/llvm/3_9/Target.source.lua > ./lib-ffi/llvm/3_9/Target.luaThat’s… really unsatisfying, so it looks like if I keep with this experiment, I’m going to eventually need something like a build script.
generate.lua
3,135 words into this blog post, I am finally ready to start writing code! I translate the most minimal chunk of the llvm-c-kaleidoscope project’s main file into Lua as can stand alone:
require("config") require("lib-lua/import") require("lib-ffi/import") class.Builder() function Builder:_init(moduleName) self.llvm = { module = LLVM.LLVMModuleCreateWithName(moduleName), builder = LLVM.LLVMCreateBuilder() } local enginePtr = ffi.new("LLVMExecutionEngineRef[1]") local msgPtr = ffi.new("char *[1]") if LLVM.LLVMCreateExecutionEngineForModule(enginePtr, self.llvm.module, msg) == 1 then local err = ffi.string(msgPtr[0]) LLVM.LLVMDisposeMessage(msgPtr[0]); error("LLVMCreateExecutionEngineForModule error: " + err) end self.llvm.engine = enginePtr[0] self.llvm.passManager = LLVM.LLVMCreateFunctionPassManagerForModule(self.llvm.module) LLVM.LLVMAddTargetData(LLVM.LLVMGetExecutionEngineTargetData(self.llvm.engine), self.llvm.passManager); LLVM.LLVMAddPromoteMemoryToRegisterPass(self.llvm.passManager); LLVM.LLVMAddInstructionCombiningPass(self.llvm.passManager); LLVM.LLVMAddReassociatePass(self.llvm.passManager); LLVM.LLVMAddGVNPass(self.llvm.passManager); LLVM.LLVMAddCFGSimplificationPass(self.llvm.passManager); LLVM.LLVMInitializeFunctionPassManager(self.llvm.passManager); end function Builder:dump() LLVM.LLVMDumpModule(self.llvm.module) end function Builder:dispose() LLVM.LLVMDisposePassManager(self.llvm.pass_manager); LLVM.LLVMDisposeBuilder(self.llvm.builder); LLVM.LLVMDisposeModule(self.llvm.module); end builder = Builder("main") builder:dump()
Here I create a single empty "module", and I dump the corresponding LLVM IR. I run it and:
; ModuleID = 'main'
It works! I don’t know what a module is yet— I assume it corresponds to an object file— but I’ve at least demonstrated I can talk to LLVM and not crash.
Here’s the project I’ve written so far. I want to go a little further than this, though. I want to make an executable.
Emitting to a file
Assuming a module is an object file, there are two things I need to do from here: I need to add a "main" function as entry point; and I need to write the object file to disk. I attempt the second thing first, since I assume it will be easier. This assumption is wrong.
The Kaleidoscope sample program doesn’t emit files— it uses JIT— so this is the first LLVM thing I’m left to do on my own. I investigate. Apparently the way you emit a module as an object file is LLVMTargetMachineEmitToFile(). This function is a bit of a monster. It takes two configuration arguments, one of which is a complex structure called a TargetMachine whose constructor takes seven arguments, many of which are magic strings.
At this point I’m starting to feel the limitations of the LLVM documentation. There’s no documentation for LLVM-C as such, so I wind up looking everything up twice, once in the LLVM-C reference to figure out what the corresponding C++ function is, then into the C++ documentation to find out what the function actually does. Once I find the function I want, the explanation is invariably limited to the strict function definition; questions like "but when do I call this?" or "but where does the TargetMachine come from?" are outside the scope of the reference document. But the reference document is the only document, so at that point I’m left searching StackOverflow. Meanwhile StackOverflow only helps when the thing I want to do is common; in the case of emitting an object file, apparently this is enough of a weird or at least power-usery thing that most entry-level LLVM users don’t attempt it. Apparently everyone else is using a command line tool called llc that converts LLVM IR to object files.
The arguments to LlvmCreateTargetMachine() are complicated because LLVM is a cross-compiler; it could compile for your machine you’re sitting at, or some arbitrary number of other machines. How do I get the specification for the machine I am sitting at? I decide to pull up the source code for llc and see what it did. And it turns out there are a bunch of functions for exactly this, returning defaults corresponding to your current machine! Things like getDefaultTargetTriple() and getFeaturesStr(). These functions are in sys.h and CommandFlags.h. Of the C++ headers. They’re not exposed to C. Um.
I need to specify eight things: a "target", a "triple", a "CPU", a "features" list, and four options related to optimization and what you’re building (library, executable, etc). The last four are thankfully enums, so those are easy to work out just from looking at the headers, and I find a function that can derive the "target" from the "triple", so now I’m down to three mysteries. I know how to look up the "triple" for my own machine, but again I don’t want this software bound to one computer. I wind up begging on IRC and Twitter for about 48 hours, and people who have done this before help me out. What I find out:
- The "triple" is the same "what do I compile?" string all compilers use; you can get a sample from any one compiler on a given machine with
clang -versionorgcc -dumpmachine. - There is after all a C-exposed
LLVM.LLVMGetDefaultTargetTriple(). (I apparently missed this in my first few scans of the five thousand lines of headers.) - "CPU" is the same as -march on a traditional compiler— it specifies microarchitecture. If you specify
armv7here, you’ll get optimizations that the armv6 can’t support, but your software also won’t run on armv6 anymore. - The "CPU" and "features" strings can be empty strings. If you do this, it gives you the most conservative possible microarchitecture for the triple you asked for. (Which might be closer to what you want anyway than the "defaults"
sys.hwould give you— after all, ask for the "default" on a brand new PC and you might get something no one else can run.) - The "target" is something weird and LLVM-internal, and refers to which LLVM backend you want to run. You’ll want to get this by using the function I mentioned that derives it from the triple. (You can also look up targets by name, but the names are pretty arcane— there’s no apparent consistency or correspondence to the outside world in the naming scheme, it was just up to whoever wrote that one LLVM add-on. For example there’s one
x86target that works with both x86 and x86-64, but the 32 and 64 bit ARM targets are separate.)
Armed with all of this, I’m able to put together an emission function which populates everything from the default triple (with overloading allowed via config.lua):
function Builder:emitToFile() local targetRefPtr = ffi.new("LLVMTargetRef [1]") compileTriple = config.compileTriple or LLVM.LLVMGetDefaultTargetTriple() compileCpu = config.compileCpu or "" compileFeatures = config.compileFeatures or "" if LLVM.LLVMGetTargetFromTriple (compileTriple, targetRefPtr, errPtr) == 1 then llvmErr("LLVMGetTargetFromTriple") end if LLVM.LLVMTargetMachineEmitToFile( LLVM.LLVMCreateTargetMachine(targetRefPtr[0], compileTriple, compileCpu, compileFeatures, LLVM.LLVMCodeGenLevelAggressive, LLVM.LLVMRelocDefault, LLVM.LLVMCodeModelSmall), self.llvm.module, cstring(self.moduleName .. ".o"), LLVM.LLVMObjectFile, errPtr) == 1 then llvmErr("LLVMTargetMachineEmitToFile") end end
And then things get weird.
My first sign of trouble is a cryptic message Unable to find target for this triple (no targets are registered). I waste time assuming I fed the function a bad triple before realizing what this really means: there are no targets, at all. It turns out before LLVMGetTargetFromTriple() will work, you have to call a special function to initialize any targets you might want to hypothetically load. There is a different initialization function for each target— LLVMInitializeAArch64Target() for 64-bit ARM vs LLVMInitializeX86Target(), for example. They apparently did it this way because most users link LLVM into their program statically, and partitioning the target backends into functions like this means you don’t have to pack the support code for whatever "MSP430" is in to your binary if you don’t plan to support it. That makes sense, but I’m linking dynamically, and I don’t know which platforms I do or don’t support ahead of time.
What a user like me— using the dynamic LLVM, not really certain what they intend to support— usually does is call the LLVMInitializeAllTargets() function. Which is defined in Target.h…
/** LLVMInitializeAllTargets - The main program should call this function if it wants to link in all available targets that LLVM is configured to support. */ static inline void LLVMInitializeAllTargets(void) { #define LLVM_TARGET(TargetName) LLVMInitialize##TargetName##Target(); #include "llvm/Config/Targets.def" #undef LLVM_TARGET /* Explicit undef to make SWIG happier */ }
…as an inline function. And now I’m stuck. LuaJIT can’t call those— at all. Again, LuaJIT calls functions by loading them from a dynamic library, but inline functions aren’t in the dynamic library, they’re C code embedded directly in the header file.
I get around this by doing something truly horrible. LLVMInitializeAllTargets() is an inline function generated from Targets.def using C preprocessor. I’m already generating Target.lua by running the preprocessor on a Lua file, in order to clear out preprocessor directives inside the embedded C header string. So I just go ahead and, uh… generate some Lua… using the C preprocessor.
function LLVMInitializeAllTargets() #define LLVM_TARGET(TargetName) LLVM.LLVMInitialize##TargetName##Target() #include "llvm/Config/Targets.def" #undef LLVM_TARGET end
After the preprocessor runs, this gives me a Lua function that calls each of the functions that the inaccessible C LLVMInitializeAllTargets() would have been calling. I make three more of these functions (in addition to initializing the "targets" themselves, you need to also initialize the "target infos", "target MCs", and "ASM printers" for each target, or you will get completely misleading error messages). And it works!
If I call my big combined LLVMInitializeAll() function first, emitToFile() prints no errors and I get a 200-byte main.o file which file claims to be Mach-O 64-bit.
Okay! Now can I actually do something?
Doing something
My module needs some code. Let’s do the simplest possible thing: Call printf.
LLVM modules keep a symbol table containing all known functions. When the operating system tries to run the exe I’m making, it will start by looking up a function named "main" in this symbol table and calling it.
local mainType = LLVM.LLVMFunctionType(LLVM.LLVMVoidType(), nil, 0, false) local mainFn = LLVM.LLVMAddFunction(builder.llvm.module, "main", mainType)
I construct the type for a main function, then construct the function itself. AddFunction will add the function to the symbol table and then return the new function object.
local mainEntry = LLVM.LLVMAppendBasicBlock(mainFn, "entry") LLVM.LLVMPositionBuilderAtEnd(builder.llvm.builder, mainEntry)
Since I will be adding code to the function, I need to create a "basic block" for the code to live in. "Basic block" is a standard term from compilers referring to a continuous section of code without any branches in it.
Earlier, I made a "builder object". This appears to be something like a text cursor. There’s a series of "Build" functions, and each inserts a bit of code at whatever point in the module the builder is positioned at. I add my new basic block to the function object, and then I position my builder at the end of the basic block. The basic block takes a name when you create it; as far as I can tell this name is arbitrary, and I assume it’s only there in case you want to direct a jump there from the end of some other basic block. I name it "entry".
Next I want to call printf. But first I have to tell LLVM what printf is:
local printfParams = ffi.new("LLVMTypeRef [1]") printfParams[0] = LLVM.LLVMPointerType(LLVM.LLVMInt8Type(), 0) -- address space 0 (arbitrary) local printfType = LLVM.LLVMFunctionType(LLVM.LLVMInt32Type(), printfParams, 1, true) -- vararg local printfFn = LLVM.LLVMAddFunction(builder.llvm.module, "printf", printfType)
Again here I’m constructing a function and putting it in the symbol table. However, this time I am not going to be adding any code to it; I’m just putting it in the symbol table so LLVM knows it exists and what type it is. Later the linker will supply the implementation to go with that symbol table entry. The type on this one is a little more complicated than the one for the main function; it has arguments.
local printString = "LET'S MAKE A JOURNEY TO THE CAVE OF MONSTERS!\n" local printfArgs = ffi.new("LLVMValueRef [1]") printfArgs[0] = LLVM.LLVMBuildGlobalStringPtr(builder.llvm.builder, printString, "tmpstring") LLVM.LLVMBuildCall(builder.llvm.builder, printfFn, printfArgs, 1, "tmpcall")
Now I’m ready to start using the builder. I Build a global string, and then I Build a call site. Both the string and the call site have "names". Like the basic block, the names appear to be arbitrary, although I cannot imagine a possible use for the names like I could with the basic block.
LLVM.LLVMBuildRetVoid(builder.llvm.builder)
Since I’m done, I cap off my basic block by returning void.
Thirteen lines of code. And that is actually all I need! My generator script spits out a new main.o and gives me a glimpse of what the code I just constructed looks like in LLVM IR:
; ModuleID = 'main' @tmpstring = private unnamed_addr constant [47 x i8] c"LET'S MAKE A JOURNEY TO THE CAVE OF MONSTERS!\0A\00" define void @main() { entry: %tmpcall = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([47 x i8], [47 x i8]* @tmpstring, i32 0, i32 0)) ret void } declare i32 @printf(i8*, ...)
That was straightforward, right? Let me take a moment to talk about what I had to do to get that thirteen lines of code.
Again, the LLVM documentation is not very helpful:
These reference documents I’ve been working with were created by Doxygen, which means unless someone went to the bother of commenting a particular function you get only these autogenerated blurbs. I mentioned that LLVMBuildCall() has a "Name" parameter and I don’t know what it does; well, what do I see if I check the documentation? Answer: The LLVMBuildCall() documentation is autogenerated and gives only a source line number. Well, but that’s LLVM-C documentation, right? What do I see if I check the "real" documentation, the C++ documentation? Answer: The IRBuilder::CreateCall() documentation is autogenerated and gives only a source line number. I never did figure out what the "Name" meant.
Now that I’ve finally got to generating ASTs I’ve encountered a new issue with the docs— many of the StackOverflow suggestions for things I need to do by this point are actually turning up as LLVM IR snippets. So now I get instructions given to me as LLVM IR, which I then have to figure out how to translate into C++, so that I can go from there to translating into C (so I can rewrite it in Lua). On the bright side though, LLVM IR turns out to be lavishly documented.
In the end, I figured out very little of the AST generation code by myself. The AST code above was constructed by consulting a mix of the llvm-c-kaleidoscope project, this tutorial written by IBM, and this sample code written by a French security researcher. The IBM and 0vercl0k samples do almost exactly the same things I’m trying to, and were tremendously helpful. But even coding with these great models to follow took some tinkering, since I still had to get past a problem I didn’t really talk about so far: LLVM reacts to most unexpected inputs by crashing. For example, LLVMCreateTargetMachine() above takes an empty string as a valid input; but pass in a NULL string and you get a crash.
A lot of these crashes are pretty easy to deal with. Early on in writing the above code, I was trying to use LLVMConstString() where I should have been using LLVMBuildGlobalStringPtr(), which meant I was passing in to printf the equivalent of a char[48] instead of the equivalent of a char *. The result was an assert:
This I could deal with. It’s not as specific as it could be, but the stack is clean, and the assert gave me a line number. I found out I could get MacPorts to show me the source code to my LLVM version (sudo port patch llvm-3.9 && `port work llvm-3.9`), and this let me look up the context, and after some testing with LLVMTypeOf()/LLVMDumpType() I understood what the problem was and where to start on fixing it.
The other problems I had were… not like that. I had a bug where I was trying to call LLVMBuildGlobalStringPtr() before creating the basic block and positioning the builder; the symptom was a segmentation fault deep inside the optimization pass manager when emitting the object file. I had a bug where I was failing to end my function with a ret void; the symptom was an assert failure, again deep in the optimization pass manager, with the totally mind-boggling assert error Assertion failed: (Val && "isa<> used on a null pointer"), function doit, file Casting.h. In both of these cases, there was basically nothing I could do to understand what went wrong or how to fix it, no breadcrumb trail back to my code. I got out of both of these situations by just checking to see if there was anything the IBM/0vercl0k samples did but I didn’t, and adding those things until the crashes went away.
The reason I’m going into all this is that these various issues taught me something: This is going to be a problem. The thirteen lines of code above are very simple, but constructing them took a full day and in the end was achieved only by following someone else’s example. A lot of the things I do next I will not have examples to follow. So this tells me if I want to make any progress I’m going to need to change how I’m doing things:
- I need, at least at first, to stick to the heavily trafficked paths. There’s some entry points to this library that lots and lots of people have gone through, and some that are less heavily used. What I’m finding is whenever I veer into the second area things get difficult. As a user of LLVM-C rather than the standard libraries I’m already pushing it; I unfortunately probably can’t afford to be an outlier in other ways also. I’ll want to always code things the simple, standard way before trying anything clever, and I’m probably going to need to get used to testing LLVM IR before attempting things against the API.
- I am going to need to get used to the internals of the LLVM code. I tried pulling the source code from MacPorts; that’s not enough. I’m going to need to build my own LLVM and get debug symbols (I might have been able to figure something out with the
isa<> used on a null pointererror, for example, if I’d been able to inspect locals and find out what was null) and I’m probably going to need to read enough source code to understand the architecture of entire modules before I can understand some of the error messages I’m going to get. This is going to be, in other words, one of those libraries.
Linking
But, I now have a main.o file! Now I just have to link it and I’m done.
This part is obnoxious. My original goal was to write a program that does all the things a compiler does. But you sort of can’t write a linker. Linkers are more the domain of the operating system and its code loading system than they are the domain of language standards, and so effectively only the operating system vendor can really write one because only the OS vendor knows what the linker even does. Whatever your preferred C compiler is, it doesn’t actually link; it actually just finds the OS-supplied linker and invokes it as a command-line program. In other words, the chart I drew at the top of this post is not quite accurate. A more accurate chart would be:

To make my original claim of "no compiler" accurate I could maybe call the linker myself (thus leaving this post with instructions that only work on OS X), or maybe look into LLVM’s experimental linker lld which is someday supposed to be able to do the unthinkable and replace the OS linker. But why make things difficult? I take the cheap route:
cc main.o -o main
And my program works!
$ ./main LET'S MAKE A JOURNEY TO THE CAVE OF MONSTERS!
The Lua script that acts as this program’s "compiler" is less than a hundred lines long.
So this is pretty promising! If I can call printf, I’ve got a basis for generating programs that do much more complicated things. It’s only a couple more steps to add variables or flow control, and once I get that done I’ll be able to do fun things like making tiny DSLs out of idiomatic Lua, or maybe even prototype some low-level systems for Emily. Here‘s the source code for my final Lua scripts in this post, and I will definitely be posting more about this in future.
Any code snippets in this post, or in the BitBucket revisions linked in this post, are available under the Creative Commons Zero license.
March 2nd, 2016 at 8:20 pm
Did you ever use perl::CGI or similar?
It seems like the logical next step is a templating engine for the IR.
March 3rd, 2016 at 7:43 pm
Hey, this is really awesome! If you’re into fusing Lua with LLVM, there’s a project you might be interested in: http://terralang.org/
March 3rd, 2016 at 7:43 pm
Hi there. I, like you, am someone who has both started a project to create a sequencer(http://genesisdaw.org/) and a programming language(http://andrewkelley.me/post/intro-to-zig.html).
It’s kind of eerie reading this blog post, you have been going through the same problem solving steps I have for the same problems. Do you hang out on IRC anywhere?
March 3rd, 2016 at 8:35 pm
Regarding
“CPU” is the same as -march on a traditional compiler— it specifies microarchitecture. If you specify armv7 here, you’ll get optimizations that the armv6 can’t support, but your software also won’t run on armv7 anymore.
Am I reading this correctly? If you specify armv7 you won’t run on armv7?
March 3rd, 2016 at 9:20 pm
I’m in the same boat as Andrew and the author. First software was music stuff, used to love Fast Tracker and Impulse Tracker, other Gravis stuff (though not as much these days – Ableton has me satisfied). Now writing a language out of pure frustration, and trying to figure out options somewhere between my AST-based dog slow interpreter and emitting machine code.
I’m on #xxl on freenode if anyone wants to chat about related subjects.
March 3rd, 2016 at 10:35 pm
Amazing… :)
Having trodden similar roads myself, it was gratifying to read that I’m not the only one who stumbles over these things. When writing a tool that used LLVM-C, I too eventually fell into the habit of reading the C++ headers to understand what was going on, and I agree that the C API seems to contain pieces people have needed in the past with no pattern or overarching plan. Your approach to side-stepping the FFI call to an inline function is quite inspired! This post is timely reminder that even short pieces of code can be the product of extreme amounts of effort and relentless optimism on the part of the programmer.
March 4th, 2016 at 4:26 am
Hey there,
been there, done that.
See https://github.com/daniel-kun/omni (look at the little gif in the “Status Quo” section, it will say more than 100 words).
I have the “Code Model” (that is what I call the AST, because there is no Syntax) up for a very little, C-like language, and I have a frontend that can manipulate parts of it. However, these are not yet combined, and I stopped working on it because I am in the middle of transforming my efforts into a Web App. This will allow you to edit and run a code model in your browser, and download a compiled binary when you are finished.
Btw., you will be able to link code elements such as classes to online-ressources such as a task tracker, a diagram, a mindmap, etc. to have the whole ALM process embedded into your code base.
Sounds good? Sounds good to me.
March 4th, 2016 at 5:37 am
Interesting project! After doing a bunch of looking at LLVM-C and stuff, I decided that, for my own language/compiler project, I would just generate LLVM IR instead of call the APIs. This has some other problems — the verification of IR input into LLVM isn’t great, but the clang command-line can just take .ll files and do compilation and linking for you, so it works out pretty okay in the end.
March 4th, 2016 at 7:16 am
I just wanted you to know about clasp ( https://github.com/drmeister/clasp ), a Common Lisp implementation designed for seamless interoperability with C++. This should in particular allow you to interact with all of LLVM in Common Lisp and other relevant C++ libs.
I don’t know if clasp is mature enough for your taste or if Common Lisp rates as a nice language though. Happy hacking!
March 4th, 2016 at 2:00 pm
[…] Run Hello » Blog Archive » No Compiler – […]
March 6th, 2016 at 3:22 am
Do you have an article about generating the sounds via source code? I’m pretty interested in how you did it, since I wanna make music myself and I’m “just a coder”. ^^
March 6th, 2016 at 1:43 pm
[…] Articolo Originale: http://msm.runhello.com/p/1003 […]
March 6th, 2016 at 1:46 pm
“kung foo man”: Nope, this was a pretty long time ago. A couple songs from this process did get posted online:
http://battleofthebits.org/arena/Entry/Roar/1187/
http://battleofthebits.org/arena/Entry/My+drift/1554/
(These were for BOTB so are both almost more sample collage pieces, but I still really like My Drift.)
March 8th, 2016 at 1:33 am
As far as cryptic error messages from incorrect functions/modules, you can use the analysis functions: LLVMVerifyFunction, and LLVMVerifyModule. If you call LLVMVerifyFunction once you’ve finished generating a function, and LLVMVerifyModule just before dumping the module, it will give you helpful diagnostics about the sort of problems you mentioned. I believe the reason these aren’t run by default is that they’re relatively expensive, and you only really need them for debugging/during development – if your compiler works correctly they will never find anything.
May 24th, 2016 at 2:33 pm
[…] McClure has a good diagram about what LLVM provides for you on her […]
November 17th, 2019 at 2:37 am
I’m currently experiencing the exact same frustrations. The one thing I really don’t like is the part where you (and I) call cc. This defeats the whole purpose of using a compiler backend! I was originally going to compile my language to C and just say “this language has 1 dependency which is any C99 compiler” but I decided to try out LLVM to see if I could have more control, get better performance or get rid of external dependencies. But then I see that once everyone generates an object file, they just call clang. What? So now I’m back to where I started but with a bunch of LLVM dependencies.
What I want to do is this:
frontend -> lli OR llc+lld
In other words, I’ll emit LLVM IR and then the user can choose between interpretation (lli) or compilation (llc+lld). This should allow me to interpret, compile and link with no external dependencies and all the available LLVM optimisations. All I need to figure out is the black magic that is the linker!
This is the occult ritual that clang performs to link my object files:
“/usr/bin/ld.lld” -pie –eh-frame-hdr -m elf_x86_64 -dynamic-linker /lib64/ld-linux-x86-64.so.2 -o a.out /usr/bin/../lib64/gcc/x86_64-pc-linux-gnu/9.2.0/../../../../lib64/Scrt1.o /usr/bin/../lib64/gcc/x86_64-pc-linux-gnu/9.2.0/../../../../lib64/crti.o /usr/bin/../lib64/gcc/x86_64-pc-linux-gnu/9.2.0/crtbeginS.o -L/usr/bin/../lib64/gcc/x86_64-pc-linux-gnu/9.2.0 -L/usr/bin/../lib64/gcc/x86_64-pc-linux-gnu/9.2.0/../../../../lib64 -L/usr/bin/../lib64 -L/lib/../lib64 -L/usr/lib/../lib64 -L/usr/bin/../lib64/gcc/x86_64-pc-linux-gnu/9.2.0/../../.. -L/usr/bin/../lib -L/lib -L/usr/lib sum.o -lgcc –as-needed -lgcc_s –no-as-needed -lc -lgcc –as-needed -lgcc_s –no-as-needed /usr/bin/../lib64/gcc/x86_64-pc-linux-gnu/9.2.0/crtendS.o /usr/bin/../lib64/gcc/x86_64-pc-linux-gnu/9.2.0/../../../../lib64/crtn.o
Whatever it’s doing, it doesn’t produce a segfaulting binary, unlike my own attempts at calling ld.